Formulation of Mapped Gaussian Process¶
We take 2-body kernel as an example, for the simplicity of explanation. The local environment to be predicted is denoted as 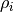 , which consists of a center atom
, which consists of a center atom 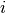 whose force is to be predicted, and all its neighbors within a certain cutoff.
whose force is to be predicted, and all its neighbors within a certain cutoff.
Energy¶
The atomic energy of from Gaussian Process regression is
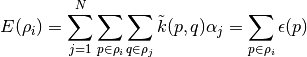
where in 2-body, 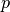 is a bond in , and
is a bond in , and 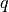 is a bond in training data
is a bond in training data 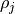 ,
, 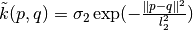 is the kernel function.
is the kernel function. 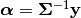 is the inverse kernel matrix multiplied by the label vector (forces of the training set).
is the inverse kernel matrix multiplied by the label vector (forces of the training set).
In the equation above, we can see that the atomic energy can be decomposed into the summation of the bond energies 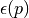 , which is a low dimension function, for n-body kernel, its dimensionality of domain is
, which is a low dimension function, for n-body kernel, its dimensionality of domain is 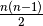 . Therefore, we use a cubic spline to interpolate this function, with a GP model with fixed training data and hyperparameters. The forces can be derived from the derivative of the above function.
. Therefore, we use a cubic spline to interpolate this function, with a GP model with fixed training data and hyperparameters. The forces can be derived from the derivative of the above function.
While in GP, the triple summations are needed in prediction, after mapping to the cubic spline, the two summations w.r.t. the training data set 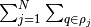 are removed. The computational cost in prediction of GP scales linearly w.r.t. the training set size
are removed. The computational cost in prediction of GP scales linearly w.r.t. the training set size 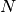 due to the two summations, and MGP is independent of .
due to the two summations, and MGP is independent of .
Uncertainty¶
The atomic uncertainty of 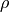 from Gaussian Process regression is
from Gaussian Process regression is
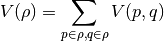

Since 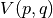 has twice the dimensionality of domain compared with , it will be expensive both in computational cost and memory if we want to interpolate directly with spline function, because a large number of grid points are needed for interpolation. To solve this problem, we observe that the 2nd term expressed in vector form is:
has twice the dimensionality of domain compared with , it will be expensive both in computational cost and memory if we want to interpolate directly with spline function, because a large number of grid points are needed for interpolation. To solve this problem, we observe that the 2nd term expressed in vector form is:
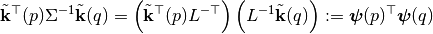
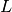 : Cholesky decomposition of matrix
: Cholesky decomposition of matrix 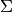 , and define
, and define 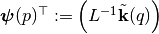 . The GP variance
. The GP variance
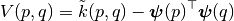
Then we use splines to map the vector function 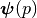 . Notice has
. Notice has 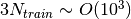 components. Have to build
components. Have to build 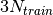 maps
maps  too many!
too many!
Dimension reduction¶
Can we find 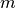 -component vector function
-component vector function 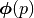 ( is small), such that
( is small), such that
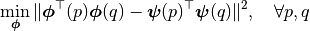
Then we can estimate the variance as
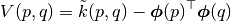
and only build maps instead of
- Principle component analysis (PCA) is what we want
- We can pick up any by picking up the rank in PCA, the higher rank, the better estimation
References¶
[1] Xie, Yu, et al. “Fast Bayesian Force Fields from Active Learning: Study of Inter-Dimensional Transformation of Stanene.” arXiv preprint arXiv:2008.11796 (2020).
[2] Glielmo, Aldo, Claudio Zeni, and Alessandro De Vita. “Efficient nonparametric n-body force fields from machine learning.” Physical Review B 97.18 (2018): 184307.
[3] Glielmo, Aldo, et al. “Building nonparametric n-body force fields using gaussian process regression.” Machine Learning Meets Quantum Physics. Springer, Cham, 2020. 67-98.
[4] Vandermause, Jonathan, et al. “On-the-fly active learning of interpretable Bayesian force fields for atomistic rare events.” npj Computational Materials 6.1 (2020): 1-11.